|
Lang Cao Hi! 👋 Here is Lang Cao, a PhD student in Computer Science at the University of Illinois Urbana-Champaign (UIUC), happily advised by Prof. Guo Yue. I interned at Microsoft Research for about one year, where I had a wonderful experience and was fortunate to collaborate with Haoyu Dong and Mengyu Zhou. I also received my Master's degree in Computer Science from UIUC and earned my Bachelor's degree from Wuhan University of Technology. I am an open researcher. My research primarily focuses on artificial intelligence (AI), particularly large language models (LLMs) and their applications. Beyond AI research, I'm also an active practitioner in Web3 and quantitative trading. |

|
ResearchMy academic research focuses on machine learning, machine reasoning, and their applications on health. Recently, I have been interested in improving the reasoning capabilities of LLMs and exploring their practical applications. My previous research experience spans various areas, including LLM Reasoning, LLM Generation, Table LLMs, AI for Health, LLM Agents, NLP Applications, as well as other topics related to LLMs and machine learning (ML). Selected research projects are listed below. |
|
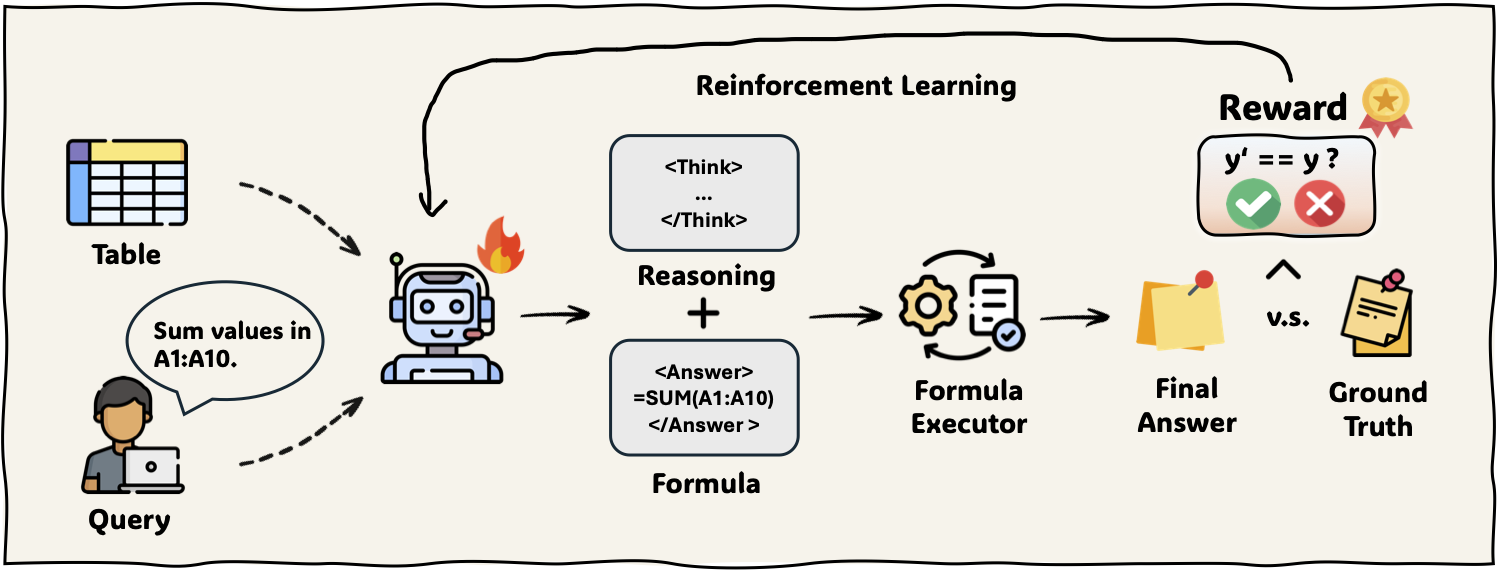
Fortune: Formula-Driven Reinforcement Learning for Symbolic Table Reasoning in Language Models
Lang Cao, Jingxian Xu, Hanbing Liu, Jinyu Wang, Mengyu Zhou, Haoyu Dong, Shi Han, Dongmei Zhang Under Review, 2025 bibtex / paper / code [Table LLMs] Formula Tuning (Fortune) is a reinforcement learning approach that enables language models to perform symbolic table reasoning by deriving executable spreadsheet formulas. |
|
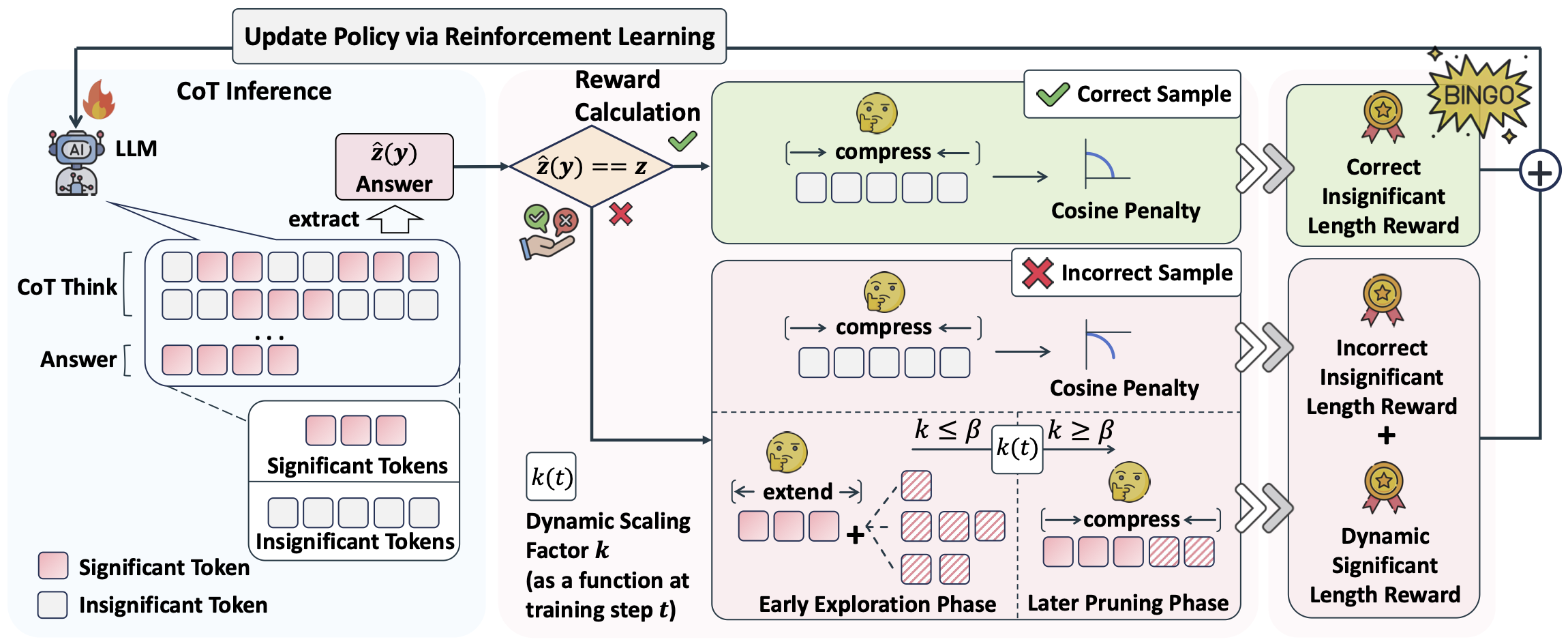
Bingo: Boosting Efficient Reasoning of LLMs via Dynamic and Significance-based Reinforcement Learning
Hanbing Liu, Lang Cao, Yuanyi Ren, Mengyu Zhou, Haoyu Dong, Xiaojun Ma, Shi Han, Dongmei Zhang Under Review, 2025 bibtex / paper / code [LLM Reasoning] Bingo is a reinforcement learning framework that trains LLMs for efficient reasoning by combining significance-aware and dynamic length rewards, improving both accuracy and efficiency across reasoning benchmarks. |
|
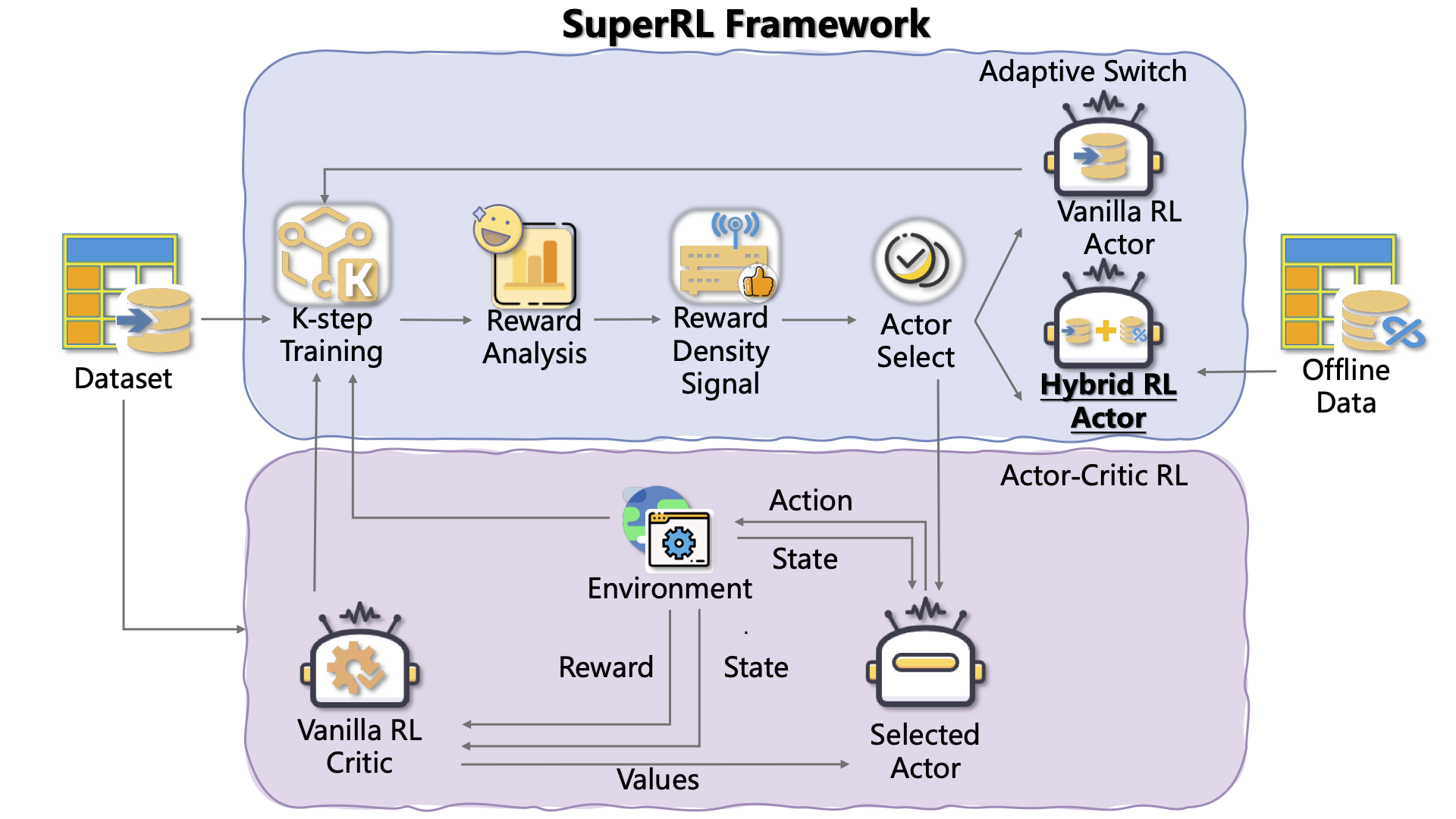
SuperRL: Reinforcement Learning with Supervision to Boost Language Model Reasoning
Yihao Liu, Shuocheng Li, Lang Cao, Yuhang Xie, Mengyu Zhou, Haoyu Dong, Xiaojun Ma, Shi Han, Dongmei Zhang Under Review, 2025 bibtex / paper / code [LLM Reasoning] SuperRL is a unified training framework that adaptively combines supervised and reinforcement learning to boost language model reasoning, achieving greater stability and generalization, especially under sparse rewards. |
|
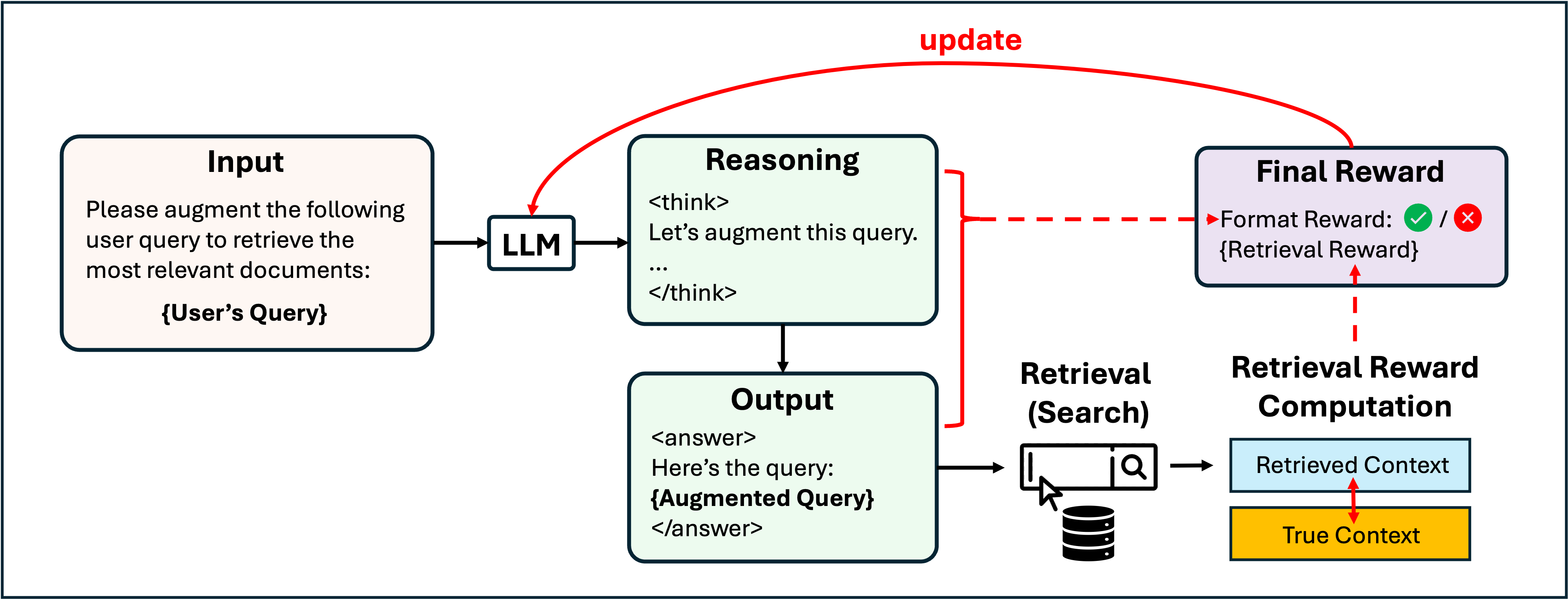
DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, Jiawei Han COLM 2025, 2025 bibtex / page / paper / code [LLM Others] DeepRetrieval is a framework that leverages reinforcement learning to hack real-world search engines and retrievers by training LLMs to perform effective retrieval tasks. |
|
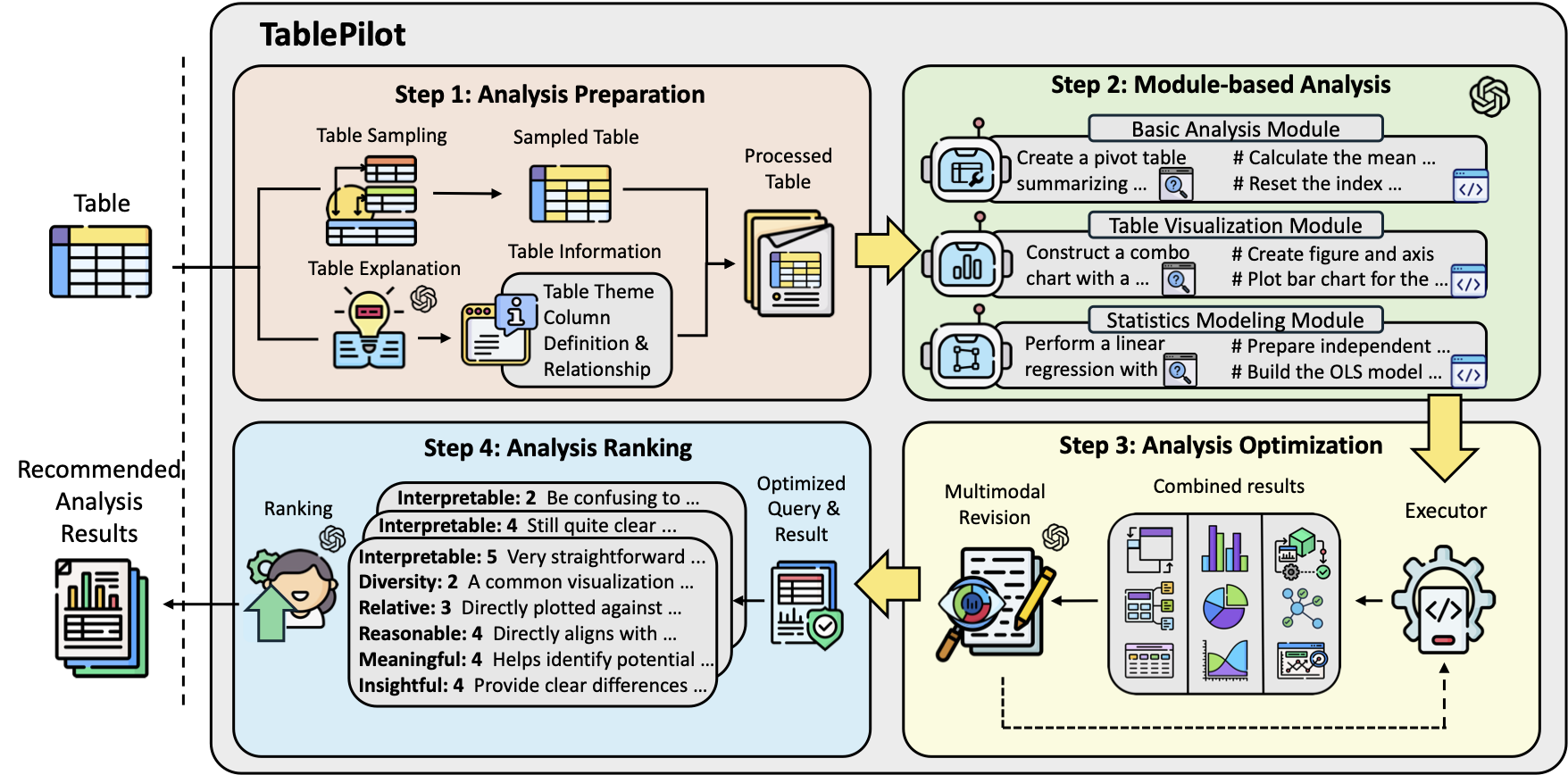
TablePilot: Recommending Human-Preferred Tabular Data Analysis with Large Language Models
Deyin Yi, Yihao Liu, Lang Cao, Mengyu Zhou, Haoyu Dong, Shi Han, Dongmei Zhang ACL 2025 Industry Track (Oral), 2025 bibtex / paper / poster / code [Table LLMs] TablePilot is a framework based on LLMs; when given an input table, it outputs recommended data analysis queries along with their corresponding code and results. |
|
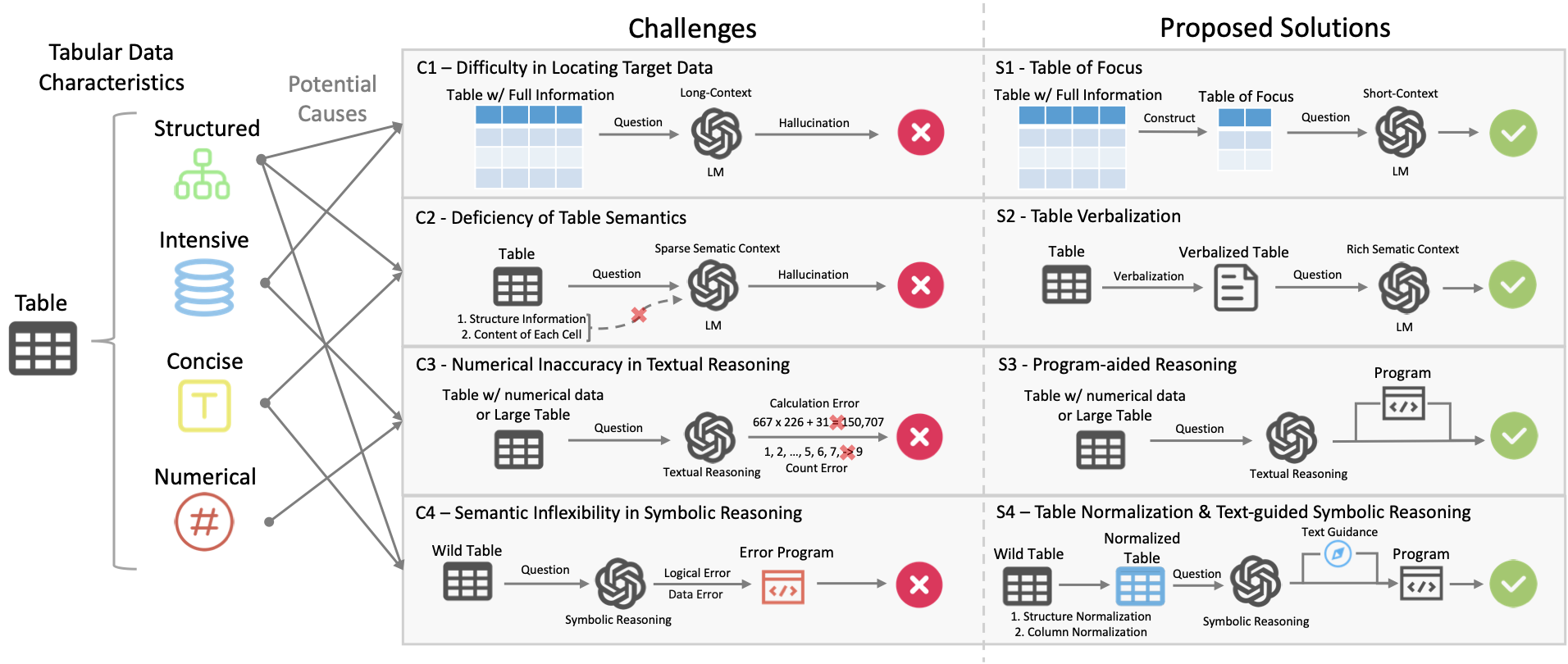
TableMaster: A Recipe to Advance Table Understanding with Language Models
Lang Cao, Hanbing Liu Under Review, 2025 bibtex / paper / code [Table LLMs] TableMaster analyzes the challenges of table understanding with language models and provides a comprehensive recipe and framework to address them. |
|
A foundation model for human-AI collaboration in medical literature mining
Zifeng Wang, Lang Cao, Qiao Jin, et al. (23 authors total), Jimeng Sun Nature Communications, 2025 bibtex / paper / code [AI for Health] LEADS is a specialized foundation model for medical literature mining that outperforms generic LLMs across multiple tasks and significantly improves accuracy and efficiency in expert workflows for evidence-based medicine. |
|
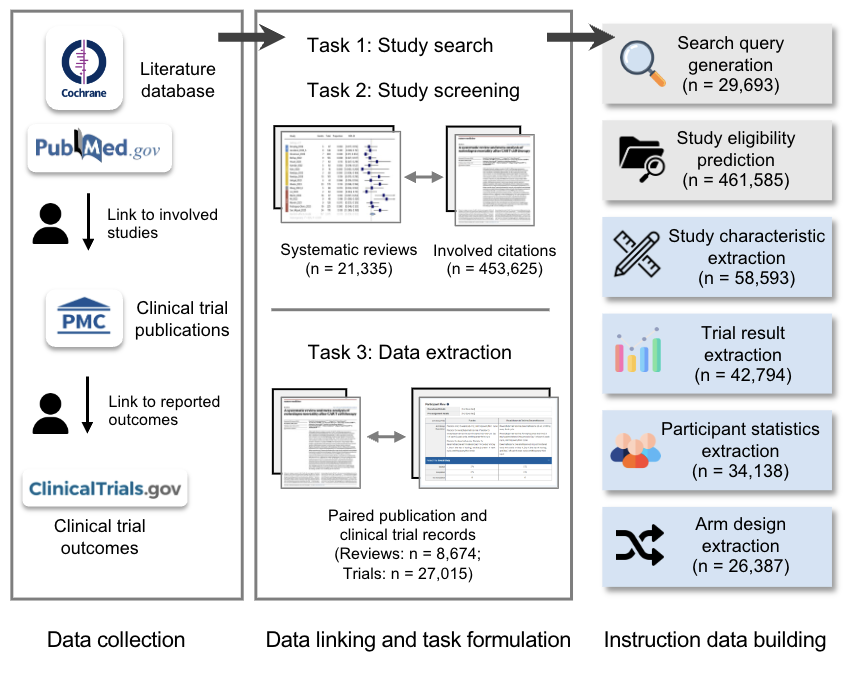
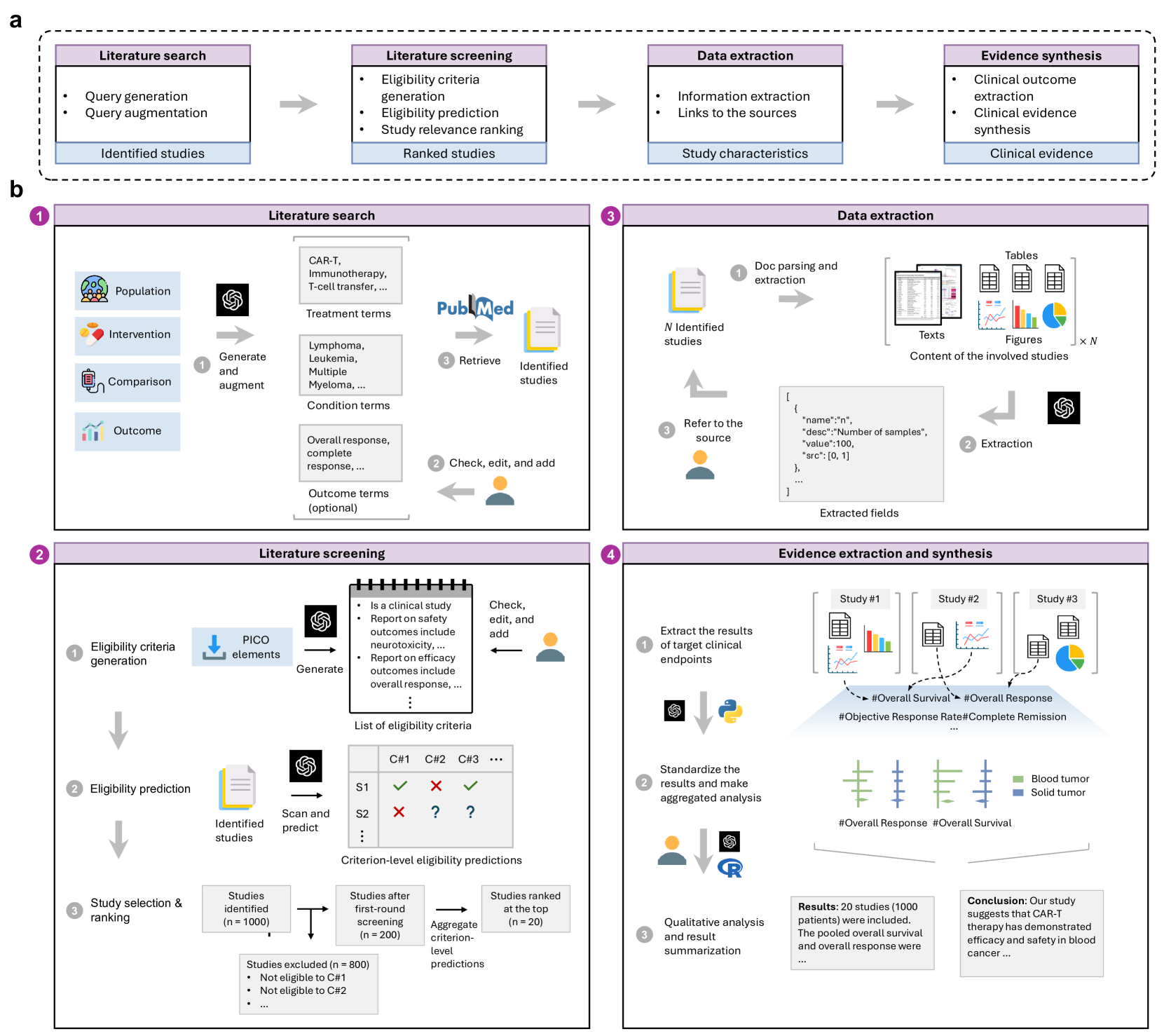
Accelerating clinical evidence synthesis with large language models
Zifeng Wang, Lang Cao, Benjamin Danek, Qiao Jin, Zhiyong Lu, Jimeng Sun npj Digital Medicine, 2025 bibtex / paper / code [AI for Health] TrialMind is a specialized generative AI system for clinical evidence synthesis that surpasses general LLMs in search, screening, and data extraction, significantly enhancing accuracy and efficiency in expert-driven systematic reviews. |
|
KG-FIT: Knowledge Graph Fine-Tuning Upon Open-World Knowledge
Pengcheng Jiang, Lang Cao, Cao Xiao, Parminder Bhatia, Jimeng Sun, Jiawei Han NeurIPS 2024, 2024 bibtex / paper / code [LLM Others] KG-FIT enhances knowledge graph embeddings by integrating LLM-guided hierarchical semantics with KG structure, achieving significant performance gains in link prediction across multiple benchmarks. |
|
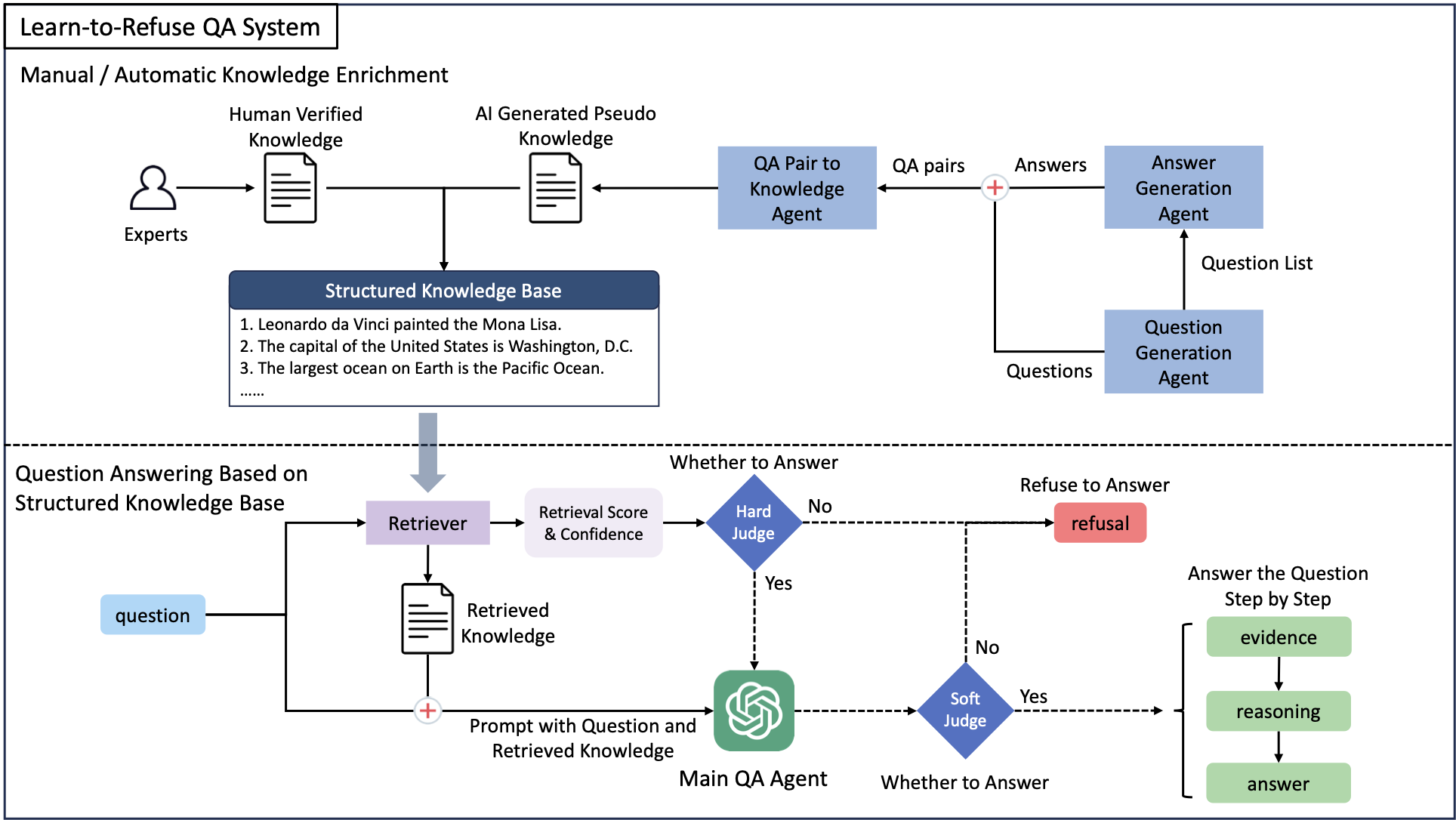
Learn to Refuse: Making Large Language Models More Controllable and Reliable through Knowledge Scope Limitation and Refusal Mechanism
Lang Cao EMNLP 2024 Main Conference, 2024 bibtex / paper / code [LLM Generation] Learn to Refuse (L2R) is a method empowering large language models to refuse answering difficult questions, thereby improving accuracy and reliability by utilizing a separate, expandable knowledge base. |
|
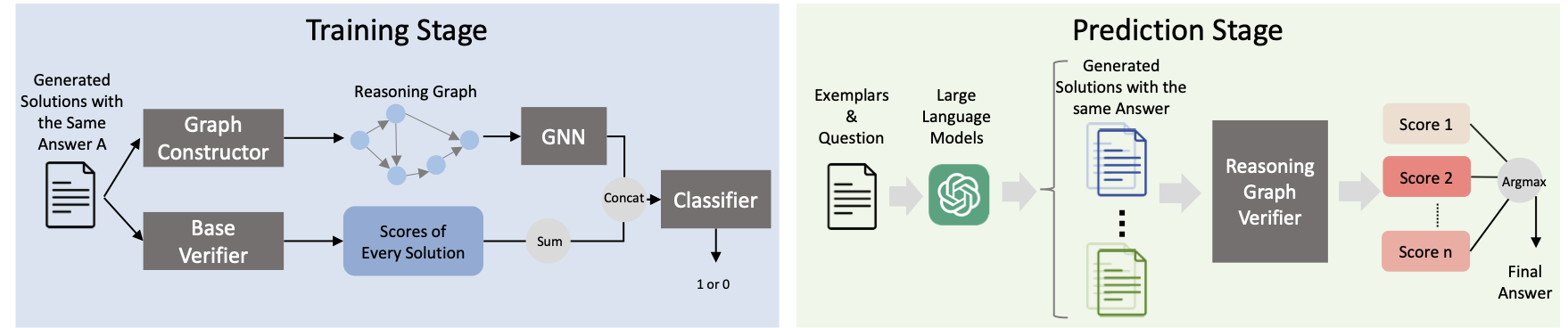
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao ACL 2024 Natural Language Reasoning and Structured Explanations Workshop, 2024 bibtex / paper / code [LLM Reasoning] GraphReason is a graph-based verification approach that enhances the reasoning capabilities of large language models by verifying the reasoning process through a graph-based framework. |
|
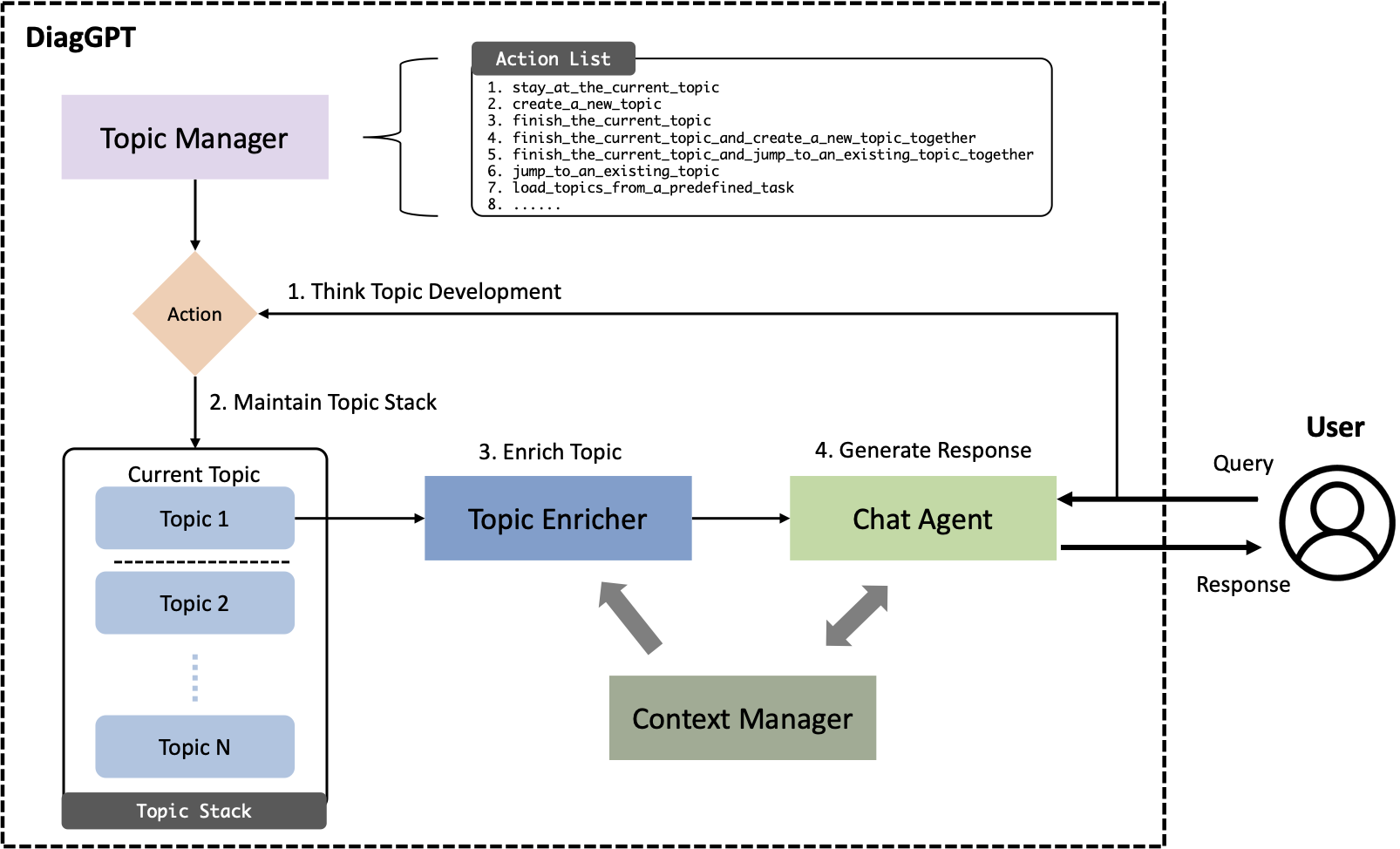
DiagGPT: An LLM-based and Multi-agent Dialogue System with Automatic Topic Management for Flexible Task-Oriented Dialogue
Lang Cao Technical Report, 2023 bibtex / paper / code [LLM Agents] DiagGPT extends large language models for task-oriented dialogue by enabling proactive question-asking and topic management, achieving strong performance in complex diagnostic interactions across domains like medicine and law. |
|
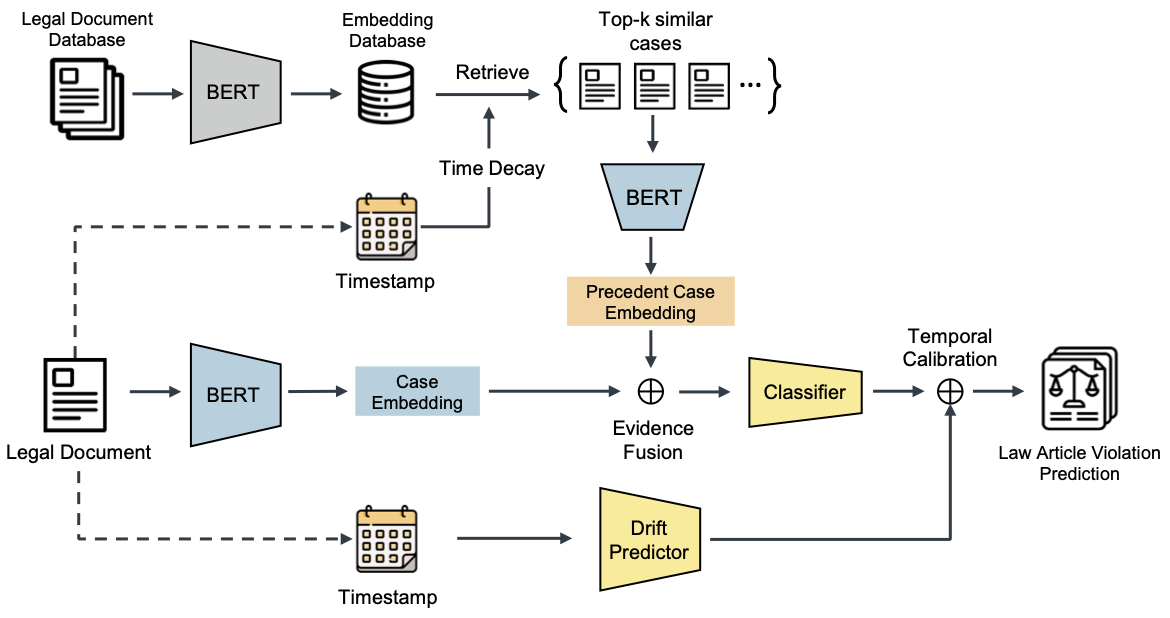
PILOT: Legal Case Outcome Prediction with Case Law
Lang Cao, Zifeng Wang, Cao Xiao, Jimeng Sun NAACL 2024 Main Conference, 2024 bibtex / paper / code [NLP Applications] PILOT is a legal case outcome prediction model for case law systems that retrieves relevant precedents and accounts for temporal legal shifts, significantly outperforming prior civil-law-focused approaches. |
|
For more research, please visit my full research page or check out my Google Scholar . |
Education and Experiences |

|
Ubiquant
May 2025 - Aug. 2025 | Shanghai, China AI and Quant Intern Research Focus: Alpha Mining, AI for Quantitative Trading, LLM Agents of Database and Deep Research. Mentor: Ziwei Yang |

|
Microsoft Research
Aug. 2024 - June 2025 | Beijing, China Research Intern at Data Knowledge and Intelligence Group Research Focus: Spreadsheet Intelligence, Table LLMs, General Machine Reasoning. Mentor: Haoyu Dong, Mengyu Zhou |

|
Tsinghua University
Nov. 2024 - Feb. 2025 | Beijing, China Research Assistant at THU-NLP Lab Research Focus: Multi-modal Learning and Reasoning. |

|
iFLYTEK
June 2021 - Aug. 2021 | Hefei, China AI Algorithm Intern at Smart Car Technology R&D Division Focus: AI Applications on Smart Cars. Mentor: Shenan Li |

|
University of Illinois Urbana-Champaign (UIUC)
Doctor of Philosophy in Computer Science Aug. 2025 - Present | Urbana, US Research Area: Machine Learning; Machine Reasoning; AI for Health Advisor: Yue Guo Master of Science in Computer Science Aug. 2023 - May 2024 | Urbana, US Research Area: AI for Healthcare; Natural Language Processing Resaerch Assistant at Sunlab Jan. 2023 - May 2024 | Urbana, US Research Focus: NLP / LLMs Applications for Healthcare and Legal. |

|
Wuhan University of Technology (WUT)
Bachelor of Engineering in Software Engineering Sept. 2018 - June 2022 | Wuhan, China Rank 1st/79, GPA 93.51/100 (3.94/4.0), National Scholarship |
Miscellanea |
Selected Rewards |
|
Invited Talks |
|
Academic Service |
|
|
|
|
© Copyright Lang Cao (last updated August 23, 2025). |